3 ES集群健康检测
Cluster Health 获取集群的健康状态,整个集群状态包括以下三种:
1.green 健康状态,指所有主副分片都正常分配
2.yellow 指所有主分片都正常分配,但是有副本分片未正常分配
3.red 有主分片未分配,表示索引不完备,写可能有问题。(但不代表不能存储数据和读取数据)
检查 ES 集群是否正常运行,可以通过 curl、Cerebro两种方式;
3.1 Curl命令检查集群状态
[root@es-node1 elasticsearch]# curl http://172.16.1.161:9200/_cluster/health?pretty=true
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 1,
"active_shards" : 2,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# 可以自定义监控项传递给zabbix监控
curl -s http://172.16.1.161:9200/_cluster/health?pretty=true | grep "status" | awk -F '"' '{print $4}'
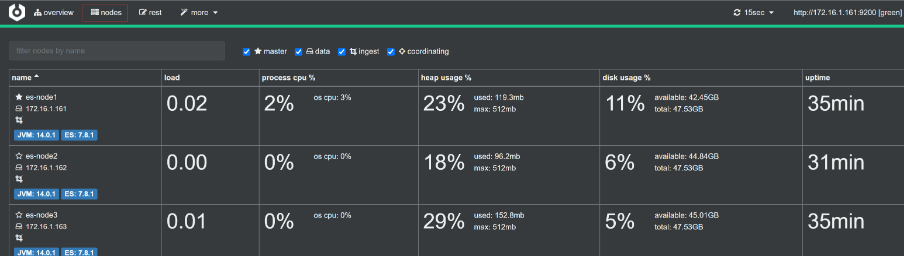
3.2 Cerebor检查集群状态
可视化 cerebro 工具检查 ES 集群状态
https://github.com/lmenezes/cerebro/releases
[root@es-node1 ~]# rpm -ivh cerebro-0.9.4-1.noarch.rpm
[root@es-node1 ~]# vim/etc/cerebro/application.conf
data.path: "/var/lib/cerebro/cerebro.db"
#data.path = "./cerebro.db"
[root@es-node1 ~]# systemctl start cerebro
[root@es-node1 ~]# netstat -lntp | grep java
tcp6 0 0 :::9000 :::* LISTEN 4646/java